
Scaling the kmax criterion in the DDCAM methodology
Palavras-chave:
Multivariate outliers, Monte Carlo simulation, Cluster analysis, Data-Driven Cluster Analysis MethodResumo
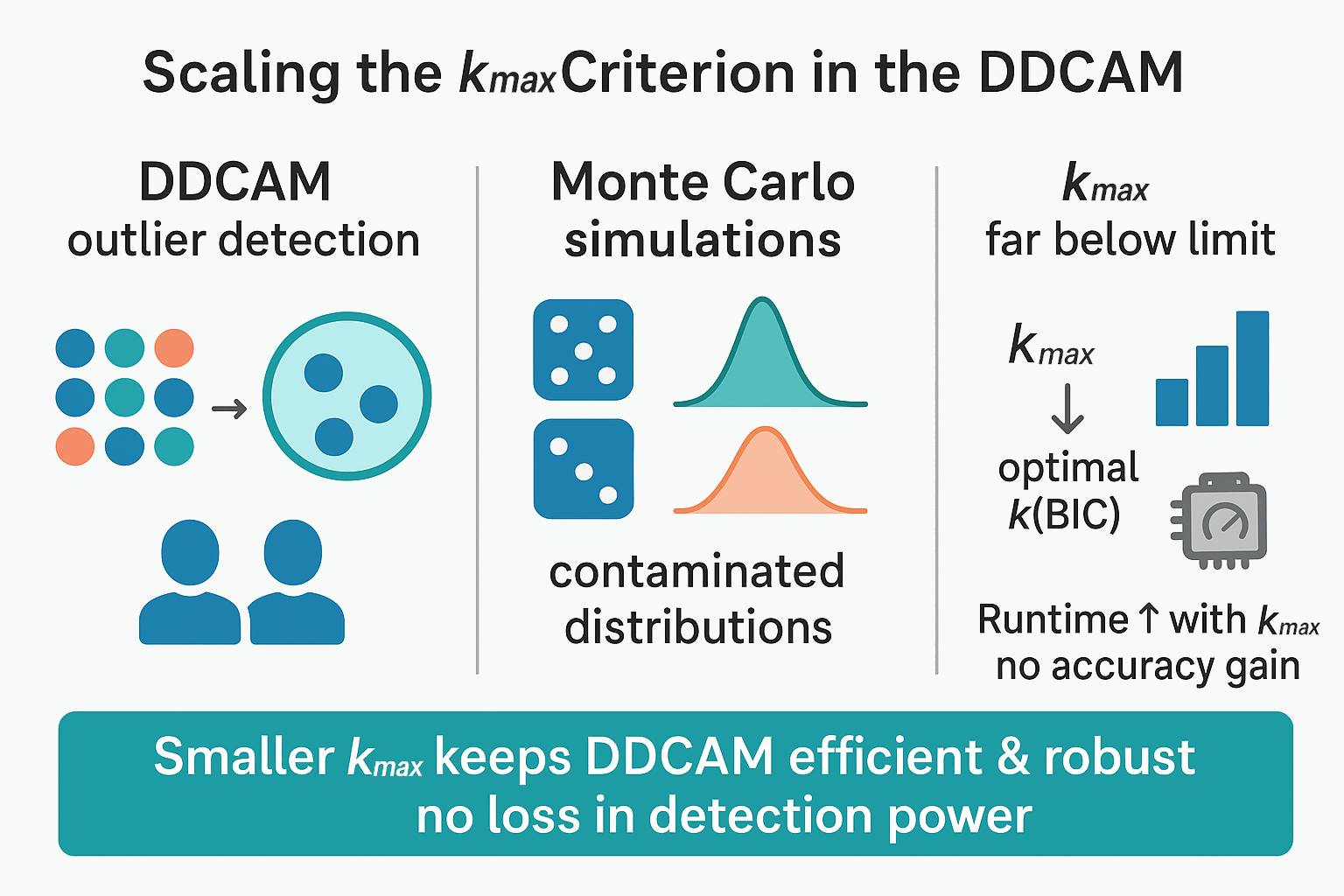
Outlier detection in multivariate data is a critical challenge with applications in fields such as finance, medicine, and industrial process monitoring. This study investigates the Data-Driven Cluster Analysis Method, designed to improve the identification of atypical observations through adaptive clustering strategies. Specifically, the research examines the role of the stopping criterion kmax —– the maximum number of clusters considered —– in determining the method’s efficiency and accuracy. Using Monte Carlo simulations with contaminated normal, exponential, and point mass distributions, the study evaluates whether excessively large kmax values contribute meaningfully to model performance or merely increase computational cost. Results demonstrate that the optimal number of clusters, selected via the Bayesian Information Criterion (BIC), consistently falls well below the imposed kmax threshold, regardless of dimensionality, or contamination level. Furthermore, as sample size increases, the gap between the selected k and the kmax limit widens, while runtime grows proportionally. These findings suggest that overly conservative settings for kmax are unnecessary and can be replaced by more parsimonious values without compromising detection accuracy. The study reinforces DDCAM’s robustness and stability while highlighting opportunities for computational optimization.
Referências
C. C. Aggarwal. An Introduction to Outlier Analysis, pages 1–34. Springer International Publishing, 2017.
J. J. Barbosa, T. M. Pereira, and F. L. P. Oliveira. Uma proposta para identificação de outliers multivariados. Ciência e Natura, 40(40):2–9, 2018.
J. J. Barbosa, A. R. Duarte, and H. S. R. Martins. A performance evaluation in multivariate outliers identification methods. Ciência & Natura, 42:e16 1–14, 2020.
V. Barnett and T. Lewis. Outliers in statistical data, volume 3. Wiley New York, 1994.
A. Cerioli. Multivariate outlier detection with high-breakdown estimators. Journal of the American Statistical Association, 105(489):147–156, 2010.
A. R. Duarte, J. J. Barbosa, H. S. R. Martins, and F. L. P. Oliveira. Data-driven cluster analysis method: a novel outliers detection method in multivariate data. Communications in Statistics-Simulation and Computation, pages 1–21, 2024.
A. R. Duarte, H. S. R. Martins, and F. L. P. Oliveira. CM-generator: an approach for generating customized correlation matrices. Communications in Statistics-Simulation and Computation, 54(2):510–529, 2025.
P. J. Filzmoser. Identification of multivariate outliers: a performance study. Austrian Journal of Statistics, 34(2):127–138, 2005.
P. J. Filzmoser, R. G. Garrett, and C. Reimann. Multivariate outlier detection in exploration geochemistry. Computers & Geosciences, 31(5):579–587, 2005.
D. M. Hawkins. Identification of outliers, volume 11. Springer, 1980.
I. T. Jolliffe and J. Cadima. Principal component analysis: a review and recent developments. Philosophical transactions of the royal society A: Mathematical, Physical and Engineering Sciences, 374(2065):20150202, 2016.
F. Kamalov and H. H. Leung. Outlier detection in high dimensional data. Journal of Information & Knowledge Management, 19(01):2040013, 2020.
T. Kutsuna and A. Yamamoto. Outlier detection using binary decision diagrams. Data Mining and Knowledge Discovery, 31(2):548–572, 2017.
C. Lejeune, J. Mothe, A. Soubki, and O. Teste. Shape-based outlier detection in multivariate functional data. Knowledge-Based Systems, page 105960, 2020.
C. Leys, O. Klein, Y. Dominicy, and C. Ley. Detecting multivariate outliers: Use a robust variant of the mahalanobis distance. Journal of experimental social psychology, 74:150–156, 2018.
J. Luo, S. Frisken, I. Machado, M. Zhang, S. Pieper, P. Golland, M. Toews, P. Unadkat, A. Sedghi, and H. Zhou. Using the variogram for vector outlier screening: application to feature-based image registration. International Journal of Computer Assisted Radiology and Surgery, 13(12):1871–1880, 2018.
A. W. Marshall and I. Olkin. A multivariate exponential distribution. Journal of the American Statistical Association, 62(317):30–44, 1967.
D. C. Montgomery and G. C. Runger. Applied statistics and probability for engineers. John wiley & sons, 2019.
R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria, 2025. URL https://www.R-project.org/.
P. J. Rousseeuw and B. C. Van Zomeren. Unmasking multivariate outliers and leverage points. Journal of the American Statistical Association, 85(411):633–639, 1990.
C. Ruwet and G. Haesbroeck. Impact of contamination on training and test error rates in statistical clustering. Communications in Statistics—Simulation and Computation, 40(3):394–411, 2011.
A. Wahid and A. C. S. Rao. A distance-based outlier detection using particle swarm optimization technique. In Information and Communication Technology for Competitive Strategies, pages 633–643. Springer, 2019.
B. Wang and Z. Mao. Outlier detection based on gaussian process with application to industrial processes. Applied Soft Computing, 76:505–516, 2019.
C. Wang, Z. Liu, H. Gao, and Y. Fu. Vos: A new outlier detection model using virtual graph. Knowledge-Based Systems, 185:104907, 2019.
J. Zhu, W. Jiang, A. Liu, G. Liu, and L. Zhao. Effective and efficient trajectory outlier detection based on time-dependent popular route. World Wide Web, 20(1):111–134, 2017.
Downloads
Publicado
Como Citar
Edição
Seção
Licença
Proposta de Política para Periódicos de Acesso Livre
Autores que publicam nesta revista concordam com os seguintes termos:
- Autores mantém os direitos autorais e concedem à revista o direito de primeira publicação, com o trabalho simultaneamente licenciado sob a Licença Creative Commons Attribution que permite o compartilhamento do trabalho com reconhecimento da autoria e publicação inicial nesta revista.
- Autores têm autorização para assumir contratos adicionais separadamente, para distribuição não-exclusiva da versão do trabalho publicada nesta revista (ex.: publicar em repositório institucional ou como capítulo de livro), com reconhecimento de autoria e publicação inicial nesta revista.
- Autores têm permissão e são estimulados a publicar e distribuir seu trabalho online (ex.: em repositórios institucionais ou na sua página pessoal) a qualquer ponto antes ou durante o processo editorial, já que isso pode gerar alterações produtivas, bem como aumentar o impacto e a citação do trabalho publicado (Veja O Efeito do Acesso Livre).
