
Avaliação de similaridade entre clusterizações hierárquica e particionada: Estudo com preços de combustíveis
DOI:
https://doi.org/10.29327/2520355.14.4-6Palavras-chave:
Análise de cluster, Métodos hierárquicos e particionados, Preços de combustíveis, k-means, Distância euclidianaResumo
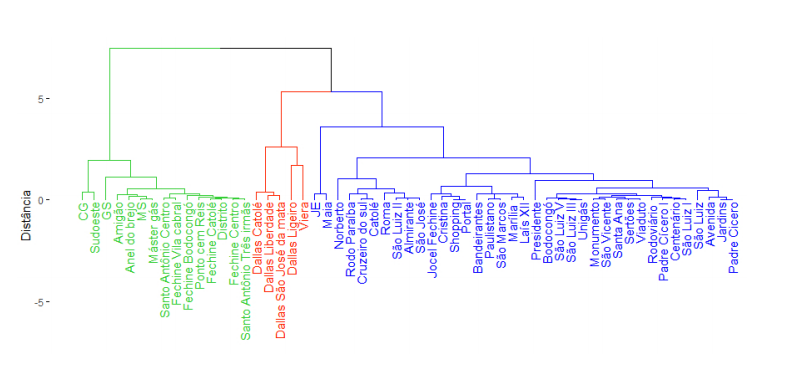
O presente trabalho teve como objetivo comparar a similaridade entre os agrupamentos gerados pelos métodos hierárquico e particionado (k-means) na análise de preços de combustíveis, utilizando dados de gasolina comum e etanol no município de Campina Grande – PB em 2019. A análise de cluster, técnica estatística multivariada, foi aplicada para classificar postos de combustíveis em grupos homogêneos, considerando a proximidade dos preços. As análises foram realizadas no software R, demonstrando a viabilidade da aplicação dessas técnicas em dados reais. No método não hierárquico (k-means), a definição do número de grupos foi feita por meio do método Elbow, sendo identificadas diferenças significativas nas médias de preços entre os grupos. No método hierárquico, empregou-se a distância euclidiana e ligação completa, os clusters obtidos apresentaram estruturas semelhantes a do k-means. A comparação entre as duas abordagens revelou consistência na formação dos grupos e na similaridade estrutural dos clusters gerados, indicando que ambos os métodos produziram resultados convergentes para a segmentação dos postos por preço evidenciando a confiabilidade das técnicas utilizadas. Conclui-se que a análise de cluster é uma ferramenta eficaz para estudos de mercado de combustíveis, e que os métodos hierárquico e particionado, embora distintos em sua abordagem, geraram agrupamentos coerentes neste contexto.
Referências
ABUSHILAH, S. F.; ABBAS, R. H. Performance evaluation of some clustering algorithms under different validity indices. Mathematical Modelling of Engineering Problems, v. 10, n. 4, p. 1271–1280, 2023.
ALBUQUERQUE, M. A. de; NASCIMENTO, E. R. do; BARROS, K. N. N. de O.; BARROS, P. S. N. Comparison between similarity coefficients with application in forest sciences. Research, Society and Development, v. 11, n. 2, p. e48511226046–e48511226046, 2022.
ALVES, K. A.; ALBUQUERQUE, O. de S.; SOUSA, A. L. de; JUNIOR, G. de M. Análise de dados dos planos de desenvolvimento institucional do instituto federal do Pará (2009-2023) utilizando o algoritmo de aprendizado de máquina k-means. Cuadernos de Educación y Desarrollo, v. 16, n. 11, p. e6259–e6259, 2024.
BUCCIANTI, A.; GOZZI, C. Cluster analysis and classification. In: Encyclopedia of Mathematical Geosciences. [S.l.]: Springer, 2023. p. 127–133.
CABEZAS, L. M.; IZBICKI, R.; STERN, R. B. Hierarchical clustering: Visualization, feature importance and model selection. Applied Soft Computing, Elsevier, v. 141, p. 110303, 2023.
CHATTAMVELLI, R. Measures of association. In: Correlation in Engineering and the Applied Sciences: Applications in R. [S.l.]: Springer, 2024. p. 1–54.
CHAVENT, M.; KUENTZ, V.; LIQUET, B.; SARACCO, J. Clustofvar: An r package for
the clustering of variables (version 1.2). 2025. Disponível em: ⟨https://CRAN.R-project.org/package=ClustOfVar⟩.
CRISPIM, D. L.; FERNANDES, L. L.; ALBUQUERQUE, R. L. d. O. Aplicação de técnica estatística multivariada em indicadores de sustentabilidade nos municípios do Marajó-pa. Revista Principia, v. 1, n. 46, p. 145–154, 2019.
DALLAL, G. F. C. et al. Flutuações no preço do petróleo e seus impactos em indicadores econômicos nacionais. Florianópolis, SC., 2024. Disponível em: ⟨https://repositorio.ufsc.br/handle/123456789/261480⟩.
de Vries, A.; RIPLEY, B. D. ggdendro: Create Dendrograms and Tree Diagrams Using ’ggplot2’. [S.l.], 2024. R package version 0.2.0. Disponível em: ⟨https://andrie.github.io/ggdendro/⟩.
FALQUETO, A. A.; CEZAR, L. C. Segmentação via machine learning: Proposta de
clusterização de consumidores do e-commerce de uma empresa multinacional do varejo esportivo. HOLOS, v. 4, dez. 2022. Disponível em: ⟨https://www2.ifrn.edu.br/ojs/index.php/HOLOS/article/view/12032⟩.
FERREIRA, R.; PAIM, F. d. P.; RODRIGUES, V.; CASTRO, G.; RODRIGUES, U. V. G. S. Análise de cluster não supervisionado em r: agrupamento hierárquico. 2020. Disponível em:
⟨https://www.infoteca.cnptia.embrapa.br/infoteca/bitstream/doc/1126478/1/5360.pdf⟩.
GAO, C. X.; DWYER, D.; ZHU, Y.; SMITH, C. L.; DU, L.; FILIA, K. M.; BAYER, J.;
MENSSINK, J. M.; WANG, T.; BERGMEIR, C. et al. An overview of clustering methods with guidelines for application in mental health research. Psychiatry Research, Elsevier, v. 327, p. 115265, 2023
HAIR, J. F.; BLACK, W. C.; BABIN, B. J.; ANDERSON, R. E.; TATHAM, R. L. Análise multivariada de dados. [S.l.]: Bookman editora, 2009.
KASSAMBARA, A.; MUNDT, F. factoextra: Extract and Visualize the Results of Multivariate Data Analyses. [S.l.], 2020. R package version 1.0.7. Disponível em: ⟨https://CRAN.R-project.org/package=factoextra⟩.
MAECHLER, M.; ROUSSEEUW, P.; STRUYF, A.; HUBERT, M.; HORNIK, K. cluster: Cluster Analysis Basics and Extensions. [S.l.], 2025.
R package version 2.1.8.1 — For new features, see the ’NEWS’ and the ’Changelog’ file in the package source). Disponível em: ⟨https://CRAN.R-project.org/package=cluster⟩.
MALHOTRA, N. K. Pesquisa de Marketing: uma orientação aplicada . [S.l.]: Bookman Editora, 2019.
OLIVEIRA, P. L. S. de; RODRIGUES, R. L.; RAMOS, J. L. C.; SILVA, J. C. S. Identificação de pesquisas e análise de algoritmos de clusterização para a descoberta de perfis de engajamento. Revista Brasileira de Informática na Educação, v. 30, p. 01–19, 2022.
PAZ, H. O. d. Método de agrupamento multinível para dados mistos. Universidade Federal da Bahia, 2024. Disponível em: ⟨https://repositorio.ufba.br/handle/ri/40414⟩.
PEREIRA, L. G. Clusterização como técnica de apoio à decisão para um marketplace eletrônico logístico. 2023. Disponível em: ⟨https://repositorio.unifei.edu.br/jspui/handle/123456789/3965⟩.
PETROLEO, G. N. E. B. AGÊNCIA NACIONAL do. Cartilha do posto revendedor de combustíveis. 2017. Disponível em: ⟨https://www.gov.br/anp/pt-br/centrais-de-conteudo/publicacoes/cartilhas-e-guias/arq/cartilhapostorevendedor6ed.pdf⟩.
R Core Team. R: A Language and Environment for Statistical Computing. Vienna, Austria, 2024. Disponível em: ⟨https://www.R-project.org/⟩.
RAN, X.; XI, Y.; LU, Y.; WANG, X.; LU, Z. Comprehensive survey on hierarchical clustering algorithms and the recent developments. Artificial Intelligence Review, Springer, v. 56, n. 8, p. 8219–8264, 2023.
SILVA, W. E. A. Análise de cluster aplicada aos dados de preços de combustíveis na cidade de Campina Grande - PB. 31 p. — Universidade Estadual da Para´ıba, Campina Grande, 2021. Trabalho de Conclusão de Curso (Graduação em Estatística). Disponível em: ⟨http://dspace.bc.uepb.edu.br/jspui/handle/123456789/25640⟩.
WANG, F.; ZHOU, G.; XIE, J.; FU, B.; YOU, H.; CHEN, J.; SHI, X.; ZHOU, B. An automatic hierarchical clustering method for the lidar point cloud segmentation of buildings via shape classification and outliers reassignment. Remote Sensing, MDPI, v. 15, n. 9, p. 2432, 2023.
Downloads
Publicado
Como Citar
Edição
Seção
Licença
Proposta de Política para Periódicos de Acesso Livre
Autores que publicam nesta revista concordam com os seguintes termos:
- Autores mantém os direitos autorais e concedem à revista o direito de primeira publicação, com o trabalho simultaneamente licenciado sob a Licença Creative Commons Attribution que permite o compartilhamento do trabalho com reconhecimento da autoria e publicação inicial nesta revista.
- Autores têm autorização para assumir contratos adicionais separadamente, para distribuição não-exclusiva da versão do trabalho publicada nesta revista (ex.: publicar em repositório institucional ou como capítulo de livro), com reconhecimento de autoria e publicação inicial nesta revista.
- Autores têm permissão e são estimulados a publicar e distribuir seu trabalho online (ex.: em repositórios institucionais ou na sua página pessoal) a qualquer ponto antes ou durante o processo editorial, já que isso pode gerar alterações produtivas, bem como aumentar o impacto e a citação do trabalho publicado (Veja O Efeito do Acesso Livre).
